为什么大语言模型(LLM)不适用于工业生产场景?
LLM是统计模型,而工业系统受制于物理定律。将LLM简单移植到工业领域面临根本性障碍。
缺乏第一性原理的约束
LLM无法保证输出严格符合物理定律。在安全关键的工业场景,一个违反能量守恒或热力学定律的“合理”建议,可能导致灾难性事故。工业AI必须是物理可信的。
无法处理连续动态与实时性
工业过程由连续的微分方程(PDE/ODE)描述。LLM设计用于处理离散Token,却不适用于求解连续物理场,推理延迟也无法满足工业控制所需的毫秒级实时响应。
我们正在为真实的工业世界构建人工智能引擎。将物理定律与深度学习模型结合,仅需要数十个样本,在数周内,构建出通常需要上万样本和数年才能实现的高保真工业基础模型。
或者,探索我们的技术 →LLM是统计模型,而工业系统受制于物理定律。将LLM简单移植到工业领域面临根本性障碍。
LLM无法保证输出严格符合物理定律。在安全关键的工业场景,一个违反能量守恒或热力学定律的“合理”建议,可能导致灾难性事故。工业AI必须是物理可信的。
工业过程由连续的微分方程(PDE/ODE)描述。LLM设计用于处理离散Token,却不适用于求解连续物理场,推理延迟也无法满足工业控制所需的毫秒级实时响应。
我们提出L0 (第一性原理) → L4 (工业应用) 的分层架构,以L2 (装备代理模型) 为核心,
构建物理可信、可复用、可组合的工业AI基础模型开发框架。
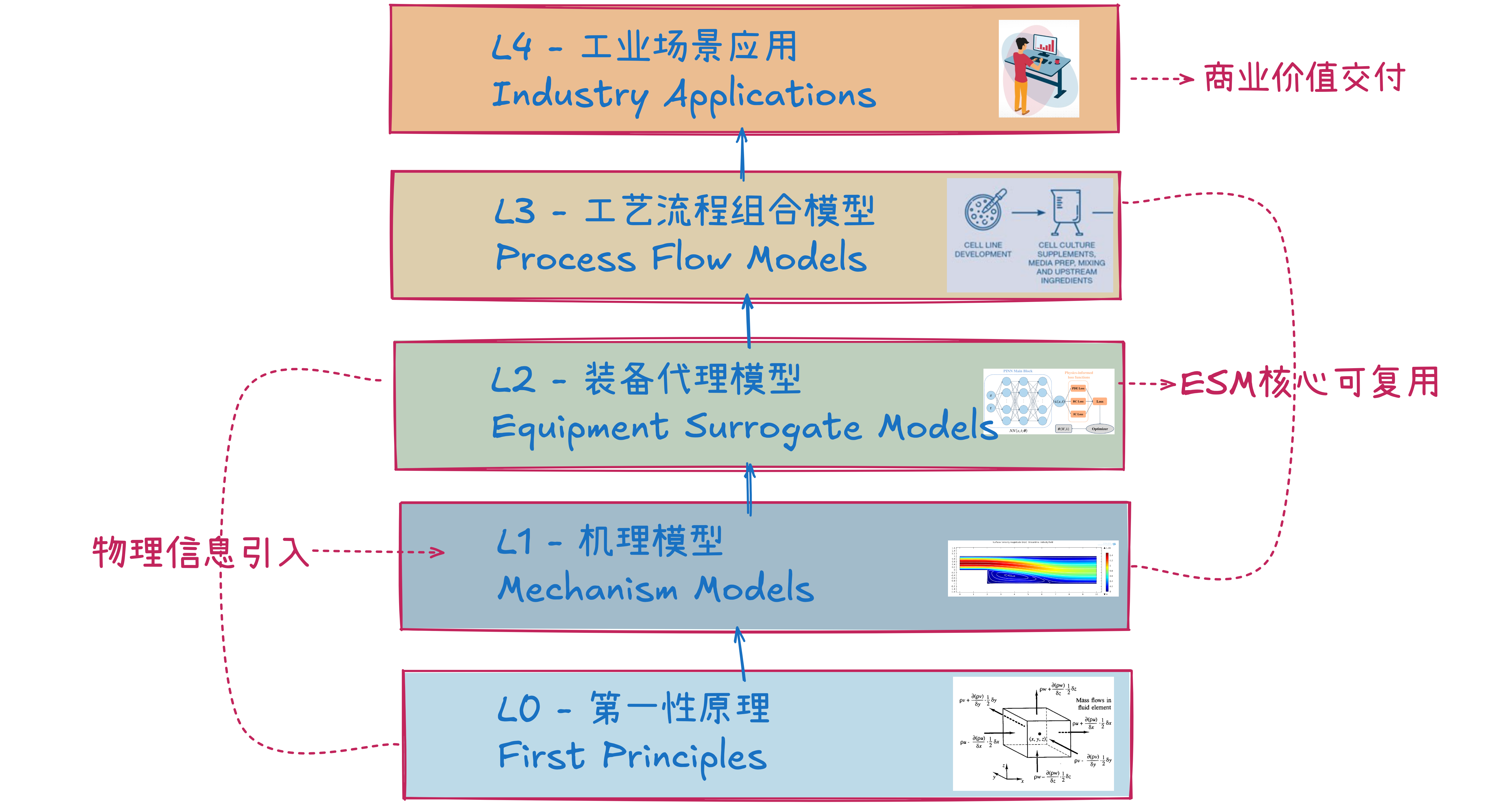
我们不只是拟合数据,我们构建具有物理约束的预训练“灰盒”AI模型。ESM(Equipment Surrogate Models)是针对特定“单元操作”(如反应器、熔炉)开发,是可规模化复用的核心构件。
少量现场工况样本
(数十个数据样本)
仿真 + 物理信息机器学习
高保真ESM (装备代理模型)
+ 工艺物理参数辨识 (可解释)
ESM通过学习机理模型(如CFD)的解空间,将数小时的物理仿真压缩到毫秒级,使实时监测和先进过程控制(APC)成为可能。
通过将物理方程(PIML机制)嵌入损失函数,ESM能利用稀疏的现场数据,逆向推导出未知的关键物理参数(如传热系数),实现对设备“物理健康状态”的可解释诊断。
ESM已掌握通用物理知识。部署到新客户现场时,仅需数十个样本数据对模型进行迁移学习和校准,极大缩短了项目周期,避免了从零开始建模的巨额成本。
我们的 ThinkMachine.work 物理AI引擎技术已经在复杂的工业数据上,与一系列强大的基线模型(包括经典深度学习、混合AI模型)进行了严格的对比测试。结果显示:其泛化能力和预测精度均实现了突破性进展。
+700%
在独立测试集上,我们的模型取得了远高于其它模型方案的R²分数。这代表着在解释过程真实动态方面超过700%的改进,实现了在“未见数据集”从失效模型到高预测力模型的泛化能力跨越。
-52%
与表现最佳的混合模型相比,ThinkMachine的ESM将归一化预测误差降低了一半以上。这表明,仅根据前5-10%的数据,实现对整个过程曲线的高保真度早期预测已成为可能。
经典AI模型
ThinkMachine ESM
“在我们最近的冶金和生物制药生产基准测试中,ThinkMachine模型引擎将关键的终点预测误差降低了20%以上,这直接为生产一线带来了显著的质量提升和运营成本节省。”
工业AI的规模化来自于可复用的“单元装备”模型。我们的Foundry提供基于第一性原理的“装备代理模型(ESM)”。这些是经过仿真数据(如CFD)预训练的基础构件,可快速组合并微调适配您的特定工艺。
基于反应动力学与传质机理,模拟发酵、聚合和批次反应。服务于生物制药、化工材料与食品饮料。
基于高温传热传质与多相流机理,预测冶金精炼终点和热处理过程。服务于特种金属、先进材料与半导体。
基于流体力学(CFD)机理,优化矿物分级、油水分离效率。服务于矿业、化工与环保。
我们的模型库正在不断扩展,将覆盖更多核心单元装备。敬请期待。
我们将ESM和流程模型的通用能力,通过少样本微调,快速交付为高价值的工业场景应用解决方案。
在数字世界中进行数千次“虚拟实验”,安全、高效地找到黄金批次的工艺参数,提升产量与质量。
精确洞察并模拟不同操作对能耗与排放的影响,驱动可持续生产,实现成本与环境双赢。
从过程数据中洞察设备健康状态的细微变化(参数漂移),实现从“事后维修”到“事前预警”的跨越。
构建高保真、物理可信的虚拟工厂,让新手在零风险、可重复的模拟环境中,快速成长为专家级操作员。
物理世界的复杂性不会成为创新的障碍。我们正在寻找先驱者,共同利用第一性原理构建工业人工智能的未来。我们诚挚邀请工业界伙伴,包括生产经理、工艺专家或现场生产工程师,共同验证和扩展这一基于物理AI的ESM范式,迈向“真正的”智能制造时代。